第一个在赛时做出来的Kernel Pwn,太不容易了
防护检查
杂项检查
./run.sh脚本中启用了smap,smep,kaslr防护,此外没什么特殊的
文件系统经检验没有权限漏洞
给了Kconfig,内核版本为Linux v6.6.91,较高版本,赛时没有详细检查Kconfig中的条目
Kconfig检查
Kconfig中的CONFIG_USER_NS没有打开,意味着我们无法开辟自己的命名空间,也就无法使用pgv堆喷
slab相关的防护:
1 | # |
注意
CONFIG_RANDOM_KMALLOC_CACHES=y这个选项,之后会体现其作用
在slab分配器的防护基本都打开了,意味着我们很难进行利用slab
逆向分析
IDA反编译发现程序很复杂,尤其是memem_ioctl函数,第一眼还以为被ollvm混淆了
初始化函数创建了一个名为/dev/mememe的设备,并提供了open, read, write和ioctl等功能
先分析mememe_open函数,发现程序调用了两个kmalloc,一个alloc_page
前两个kmalloc貌似被随机化了,无法静态分析其使用的是哪一个slab,后一个alloc_page申请的是order-0的page,并转成虚拟地址赋值给了一个地址偏移量。
事实上,这种缓解策略叫Random kmalloc caches,是前文
CONFIG_RANDOM_KMALLOC_CACHES=y选项提供的
它的作用大概是为每个大小引入了多个通用 slab 缓存,在调用时通过返回地址(ret_addr)和随机数(random_kmalloc_seed)伪随机选择其中一个使用
效果如下所示
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
slabinfo - version: 2.1
...
kmalloc-rnd-15-8k 0 0 8192 4 8 : tunables 0 0 0 : slabdata 0 0 0
kmalloc-rnd-15-4k 8 8 4096 8 8 : tunables 0 0 0 : slabdata 1 1 0
kmalloc-rnd-15-2k 32 32 2048 8 4 : tunables 0 0 0 : slabdata 4 4 0
kmalloc-rnd-15-1k 32 32 1024 8 2 : tunables 0 0 0 : slabdata 4 4 0
kmalloc-rnd-15-512 48 48 512 8 1 : tunables 0 0 0 : slabdata 6 6 0
kmalloc-rnd-15-256 80 80 256 16 1 : tunables 0 0 0 : slabdata 5 5 0
kmalloc-rnd-15-192 42 42 192 21 1 : tunables 0 0 0 : slabdata 2 2 0
kmalloc-rnd-15-128 64 64 128 32 1 : tunables 0 0 0 : slabdata 2 2 0
kmalloc-rnd-15-96 42 42 96 42 1 : tunables 0 0 0 : slabdata 1 1 0
kmalloc-rnd-15-64 128 128 64 64 1 : tunables 0 0 0 : slabdata 2 2 0
kmalloc-rnd-15-32 128 128 32 128 1 : tunables 0 0 0 : slabdata 1 1 0
kmalloc-rnd-15-16 512 512 16 256 1 : tunables 0 0 0 : slabdata 2 2 0
kmalloc-rnd-15-8 1024 1024 8 512 1 : tunables 0 0 0 : slabdata 2 2 0
kmalloc-rnd-14-8k 4 4 8192 4 8 : tunables 0 0 0 : slabdata 1 1 0
kmalloc-rnd-14-4k 8 8 4096 8 8 : tunables 0 0 0 : slabdata 1 1 0
kmalloc-rnd-14-2k 16 16 2048 8 4 : tunables 0 0 0 : slabdata 2 2 0
...该缓解方法还是由华为工程师提出来的,
华为为我增智慧了
仔细分析发现程序中貌似有个结构体,memset函数之后有很多地址赋值语句,不同的偏移地址赋值代表着不同的字段,不过目前还不清楚它们大部分的功能。
字段名称是之后补充的
1 | ... |
mememe_read与mememe_write内容较少且个防护很严格的,简单审计mememe_release函数发现没有UAF,直接分析mememe_ioctl函数
IDA并没有很好地处理这里的逻辑,静态分析很难受
分析发现该函数大概以中间的memset函数分为两小部分,且后半部分一直在用if或switch检验某个固定的变量的值,猜想是虚拟机指令处理部分,对不同的id执行不同的函数
结合之前的结构体以及程序逻辑,逆向还原虚拟机结构体:
1 | struct vmmem // sizeof=0xB8 |
其中page字段是alloc_page得到的order-0 page,里边存放的是将要分析的虚拟机指令,kmap字段为kmalloc得到的空间,存放栈顶元素,stack字段是虚拟机栈,rsp字段指向栈顶。
虚拟机指令结构体,各种指令操作如下所示:
立即数直接用
uint32_t会导致padding到8字节,或许需要显式align一下
1 | struct insn { // sizeof=0x6 |
其中memset函数之前的部分是检查部分,对部分指令进行了约束,防止访问越界
分析结束很容易发现有一个漏洞,由于指令都存在字段page里,我们可以利用id 12指令进行运行时修改page内原来的指令,造成page越界读和越界写原语
这个任意读/任意写的大小是DWORD(4字节),不过可以以任意偏移无限触发,还是很强大的
漏洞利用
利用思路
有了page层面的越界读写之后就好办了,我们可以通过堆喷和页级堆风水,造成该页面与cred_jar页面物理相邻的局面,在直接映射区的虚拟地址也相邻,从而利用越界写改写cred_jar直接一步提权
甚至不需要利用
mememe_read功能,因为该方法无需任何地址泄漏
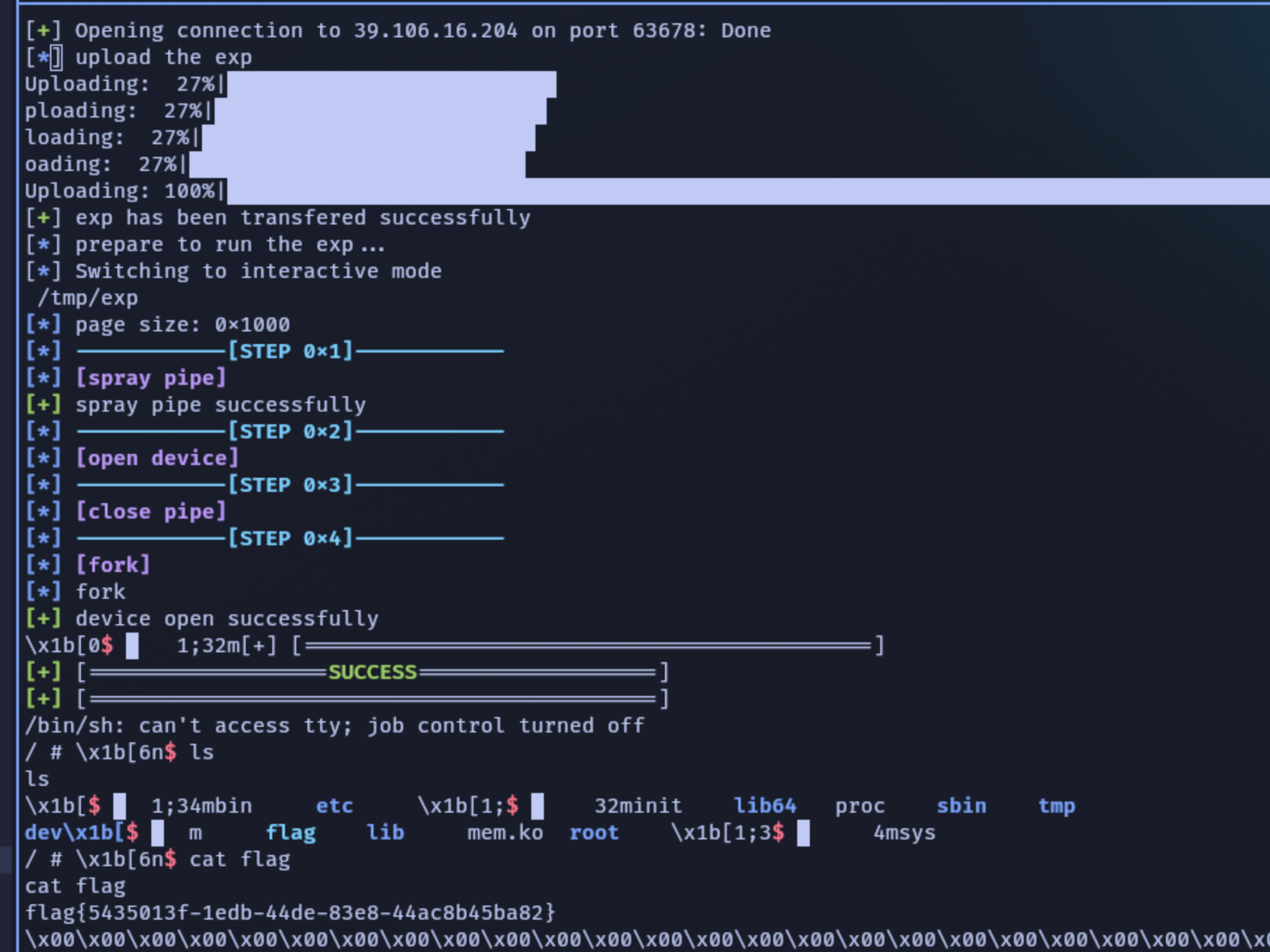
赛时策略
事实上,在构造order-0的页级堆风水应该堆喷order-1的pages,但是赛时我嫌麻烦没有去尝试pgv堆喷,而是直接堆喷pipe_buffer来获得大量的order-0 pages,这种情况下时间先后获得的两个页面大概率也物理相邻,成功率还是很高的
赛后验证发现
CONFIG_USER_NS没有打开,无法用pgv
之后的操作就是先free id为奇数的pipe_buffer造成page hole,再打开该设备/dev/mememe,此时mememe_open函数中的alloc_page很大概率会取到之前free的pipe_buffer的page hole
下一步,我的策略是把剩下的pipe_buffer全部free掉,然后再用setuid(1000)堆喷cred_jar取走刚刚free的pipe_buffer的page,此时的cred_jar大概率会申请到mememe->page的相邻地址处(假设之前的步骤都成功)
最后在大量fork提权函数,并利用越界写覆写cred_jar提权。虽然假设了不少因素,本地成功率还是很高的
远程成功率偏低了一点,大概5,6次才成功,但是本地试了十几次只有一次没有成功
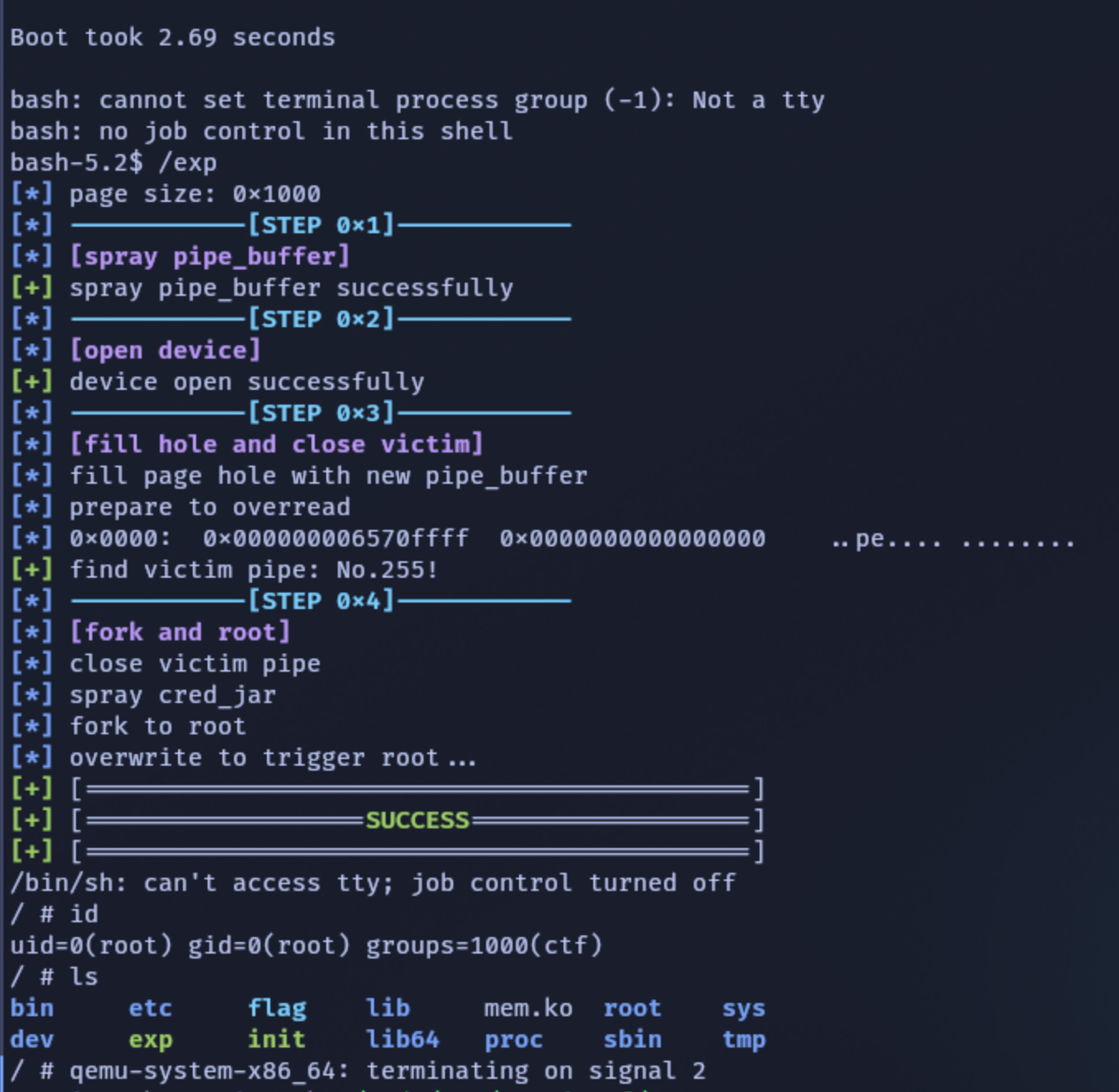
改进策略
由于无法使用
pgv堆喷,因此将现有的pipe_buffer堆喷改进了一下
赛时策略的做法只能是可堪一用,好多细节都没有把握好。二次free后的pipe_buffer造成的page hole过大,而我们的利用需要物理相邻的页面被cred_jar占用,只有一个页满足该条件,喷中的概率小了很多
因此,我们可以将没有喷中pipe_buffer的page再次填充,在第二轮free之前不存在多余的page hole
做标记的目的是方便调试寻找/判断是否命中
1 | ... |
虽然mememe_read理论上不需要用,但是我们可以用page越界读获取被溢出的victim page的信息,从而靶向free特定的pipe_buffer,只在物理相邻的页中留下free page,提高成功率
1 | ... |
此时仅free了物理相邻的(即可被越界写)的page,之后再次堆喷cred_jar然后fork提权函数,有很大概率会取走该页面,理论上成功率会高得多
本地测试成功率都差不多很高,不知道远程怎么样
Exp
赛时Exp
1 |
|
改进Exp
仅给出main函数部分
1 | // NOTE: Linux Kernel exploit template |